
Dans NAM mise en œuvre première partie, nous avons exploré les différents types de modèles et présenté les principaux chargeurs logiciel et matériels disponibles actuellement. Dans cette seconde partie, nous allons présenter les différentes architectures de modèles NAM, après une petite présentation du vocabulaire associé au système NAM. On fera ensuite un point pratique sur les ressources nécessaires pour pouvoir utiliser les modèles NAM « live ». Un pack de modèles en téléchargement est par ailleurs associé à cet article afin de réaliser vos propres tests avec différentes architectures de modèles, si vous le souhaitez.
Wavenet, epochs et ESR
NAM repose sur une approche de deep learning appliquée à l’audio : un modèle NAM va produire un signal de sortie à partir d’un signal d’entrée après avoir été entrainé pour cela. Et pour ce faire, NAM s’appuie principalement sur le système Wavenet. Celui-ci à originalement été développé et mis au point par Deepmind (filiale de Google) vers 2016, et son premier champs d’application était la génération audio et plus particulièrement des applications dans le domaine de la synthèse vocale comme le text-to-speech (https://en.wikipedia.org/wiki/WaveNet). Vu d’avion, Wavenet mis en oeuvre avec NAM permet de prédire une valeur de sortie à partir d’une valeur d’entrée à travers l’utilisation d’un modèle. On génère ce modèle par apprentissage à partir d’un jeu de données source (fichier « input ») et d’un jeu de données cible, c’est à dire le résultat obtenu en envoyant le signal source à l’ampli ou à la pédale (ce qui constitue le fichier « output« ). L’apprentissage est réalisé à travers le programme « trainer » de NAM, qui construit le modèle à travers l’exécution de multiples itérations (epochs).
Le modèle obtenu réalise ses prédictions (i.e. la reproduction du son du matériel capturé) à partir d’un système de couches (layers) et en utilisant des paramètres régissant les dilatations (dilations en Anglais).
Dans le système par apprentissage par deep learning, on procède par itérations successives (les epochs) dans lesquelles on surveille l’évolution de l’ESR (Error-to-Signal Ratio, ou rapport d’erreur sur signal). Plus l’ESR se rapproche de 0 et plus le modèle est fidèle à l’original. L’obtention d’un ESR bas nécessite généralement un nombre relativement important d’itérations : les créateurs de modèles NAM utilisent fréquemment jusqu’à 800 ou 1000 epochs. Au delà d’un certain nombre d’itérations, on observe généralement un plateau à partir duquel il n’est plus intéressant de continuer l’apprentissage, les gains devenant très marginaux ou nuls au regard des couts en temps et en GPU.
Concernant l’ESR, voici quelques points de repères inspirés par la page de MOD Audio décrivant les best practices autour des captures AIDA-X (https://mod.audio/modeling-amps-and-pedals-for-the-aida-x-plugin-best-practices/) et que j’ai repris et légèrement aménagés pour les transposer à NAM :
- ESR <= 0.01 : excellente précision, le modèle est très fidèle
- 0.01 < ESR ≤ 0.05 : très bonne précision, le modèle est fidèle
- 0.05 < ESR ≤ 0.15 : bon compromis qualité/utilisation, modèle encore assez fidèle.
- 0.15 < ESR ≤ 0.35 : différences perceptibles, utilisation possible mais avec prudence.
- ESR > 0.5 : modélisation très approximative, probablement non satisfaisante
- ESR > 0.9 : très éloigné, probablement inutilisable. Niveaux, réglages et alignements à vérifier.
Nous reviendrons sur cette phase de capture et d’apprentissage dans un autre article de cette série.
Pour information, les modèles NAM sont des fichiers au format JSON qui regroupent les informations du modèle lui même et une partie métadonnées qui donne au chargeur des informations sur le modèle :
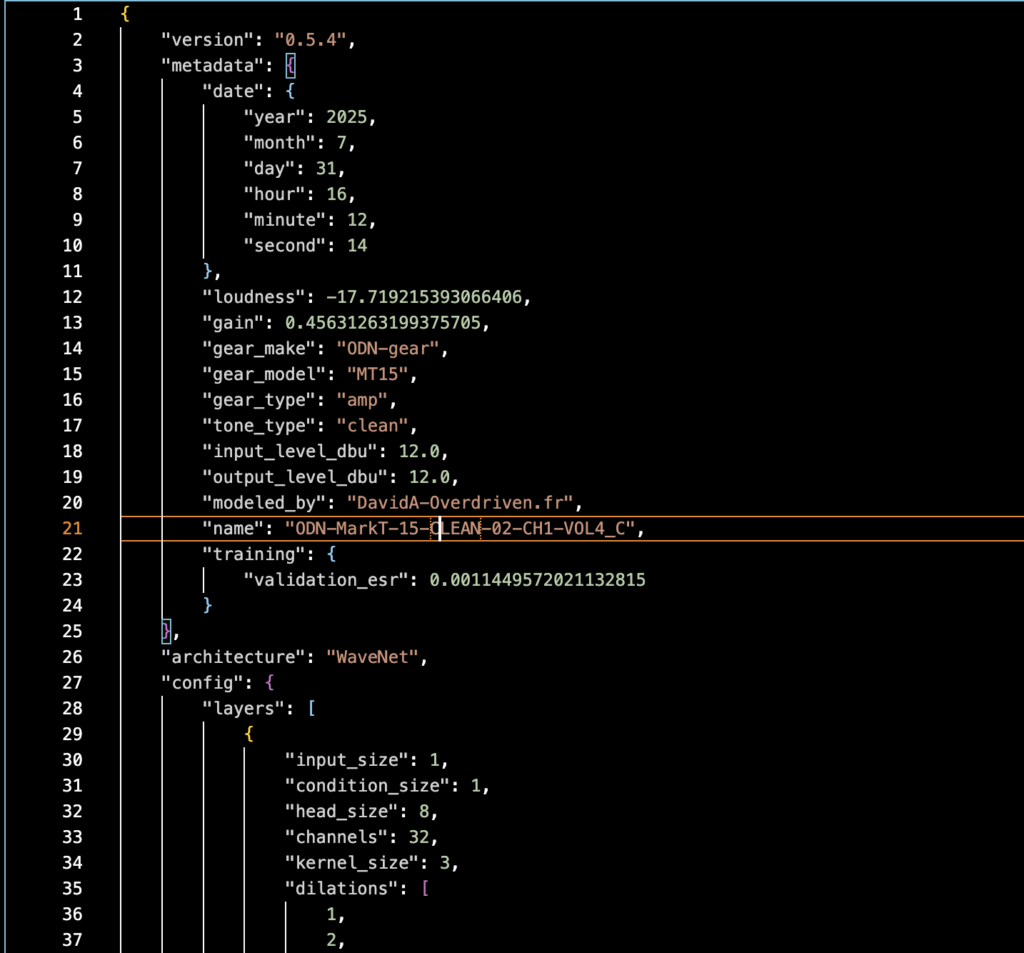
Pour en savoir plus sur les clefs utilisées dans les fichiers NAM, vous pouvez explorer le contenu de fichiers .NAM par vous-même et consulter la petite documentation présente ici : https://neural-amp-modeler.readthedocs.io/en/latest/model-file.html#
Architectures NAM
Steve Atkinson à mis au point 4 jeux de paramètres, permettant de générer 4 types de modèles pour répondre à la problématique de ressources CPU nécessaires pour mettre en oeuvre les modèles NAM. Dans le vocabulaire NAM, ces types de modèles sont désignés sous le terme d » « architectures« . Le modèle NAM de base est considéré comme l’architecture « standard » : il offre un très bon niveau de fidélité, mais il peut se révéler problématique en terme de consommation CPU pour les utilisateurs disposant de machines très peu puissantes ou anciennes, et surtout pour des plates-formes propriétaires (multi-effets ou machines comme les Raspberry Pi) qui s’appuient fréquemment sur des processeurs beaucoup moins puissants que ceux des PC/MAC -voire que ceux des iPhone-, la plupart du temps pour des raisons de couts des puces et des couts d’intégration associés. S. Atkinson a donc introduit des variantes plus légères d’architectures : ce sont les modèles LITE, FEATHER (plume) et NANO. Ces variantes impactent la taille du modèle sur disque et en mémoire, ainsi que le niveau de consommation CPU nécessaire pour les faire fonctionner.
La complexité (et la fidélité) des modèles NAM est définie à travers les différentes couches et niveaux de dilatations introduits dans la section précédente. In fine, cette complexité peut se résumer à travers le nombre de paramètres gérés par le modèle NAM :
| Architecture | Parameters | Size on disk (approx). |
|---|---|---|
| STANDARD | 13800 | 280-300 KB |
| LITE | 6600 | 141 KB |
| FEATHER | 3000 | 65 KB |
| NANO | 841 | 20 KB |
La communauté d’utilisateurs NAM a également fait émerger de nouvelles architectures de modèles, principalement les modèles xStandard et Complex. Ce dernier cherche à accroitre le niveau de fidélité et, contrairement à la démarche d’allégement présenté dans le paragraphe précédent, il demande significativement plus de puissance CPU pour fonctionner :
| Architecture | Parameters | Size on disk (approx). |
|---|---|---|
| COMPLEX | 90000 | 1.9 - 2.3 MB |
| XSTANDARD | 12400 | 270 KB |
Les différences de consommation CPU sont présentées dans une section suivante de cet article et attention, pour rappel, les modèles complexes nécessitent des machines suffisamment rapides.
Si vous débutez avec NAM et/ou que vous souhaitez explorer les rendus et comportements des différentes architectures de modèles sur votre propre matériel, je vous invite à télécharger un starter pack à partir de ce lien : https://overdriven.fr/overdriven/index.php/nam-models/#MarkT-15_pack_1_8211_extended
Ce pack contient 7 modèles de base (1 Clean, 1 Crunch , 3 high gains et 2 modèles boostés avec une OD) inspirés d’un ampli MT 15*. Ce pack est téléchargeable sur tone3000 (vous trouverez le lien sur la même page) mais cette version contient -outre les modèles Standard, xStandard et Complex présents sur Tone3000- les déclinaisons LITE, FEAHER et NANO, tous constitués à partir des mêmes fichiers ré-ampés. Et en bonus, ce pack contient des presets Genome pour pouvoir réaliser rapidement des essais. Les presets pointent par défaut les modèles _S (standard) mais vous pourrez les switcher à votre guise….
*Voir mention légale en bas d’article
Et voici ci-dessous un tableau des ESRs obtenus pour les différents modèles de ce pack :
| Model name | ESR | Loudness | Tone type |
|---|---|---|---|
| ODN-MarkT-15-CLEAN-02-CH1-VOL4_C.nam | 0.00114 | -17.7 | clean |
| ODN-MarkT-15-CLEAN-02-CH1-VOL4_F.nam | 0.01298 | -17.8 | clean |
| ODN-MarkT-15-CLEAN-02-CH1-VOL4_L.nam | 0.01058 | -17.8 | clean |
| ODN-MarkT-15-CLEAN-02-CH1-VOL4_N.nam | 0.01847 | -17.6 | clean |
| ODN-MarkT-15-CLEAN-02-CH1-VOL4_S.nam | 0.00416 | -17.8 | clean |
| ODN-MarkT-15-CLEAN-02-CH1-VOL4_XS.nam | 0.00477 | -17.6 | clean |
| ODN-MarkT-15-CRUNCH-01-CH2_C.nam | 0.00149 | -17.7 | crunch |
| ODN-MarkT-15-CRUNCH-01-CH2_F.nam | 0.00998 | -18.0 | crunch |
| ODN-MarkT-15-CRUNCH-01-CH2_L.nam | 0.00705 | -17.8 | crunch |
| ODN-MarkT-15-CRUNCH-01-CH2_N.nam | 0.02170 | -18.0 | crunch |
| ODN-MarkT-15-CRUNCH-01-CH2_S.nam | 0.00455 | -17.8 | crunch |
| ODN-MarkT-15-CRUNCH-01-CH2_XS.nam | 0.00434 | -17.9 | crunch |
| ODN-MarkT-15-HIGHGAIN-01-CH2-G3_C.nam | 0.00197 | -18.2 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-01-CH2-G3_F.nam | 0.01500 | -18.5 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-01-CH2-G3_L.nam | 0.00969 | -18.4 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-01-CH2-G3_N.nam | 0.03836 | -18.6 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-01-CH2-G3_S.nam | 0.00656 | -18.4 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-01-CH2-G3_XS.nam | 0.00535 | -18.4 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-02-CH2-G4_C.nam | 0.00235 | -18.3 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-02-CH2-G4_F.nam | 0.01980 | -18.7 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-02-CH2-G4_L.nam | 0.01292 | -18.6 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-02-CH2-G4_N.nam | 0.04332 | -18.9 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-02-CH2-G4_S.nam | 0.00822 | -18.6 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-02-CH2-G4_XS.nam | 0.00732 | -18.3 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-03-CH2-G5_C.nam | 0.00430 | -18.5 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-03-CH2-G5_F.nam | 0.02364 | -18.7 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-03-CH2-G5_L.nam | 0.01586 | -18.6 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-03-CH2-G5_N.nam | 0.05254 | -19.0 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-03-CH2-G5_S.nam | 0.00985 | -18.6 | hi_gain |
| ODN-MarkT-15-HIGHGAIN-03-CH2-G5_XS.nam | 0.00925 | -18.6 | hi_gain |
| ODN-MarkT-15-OD-01-CH1-VOL4_C.nam | 0.00078 | -17.6 | overdrive |
| ODN-MarkT-15-OD-01-CH1-VOL4_F.nam | 0.00521 | -17.6 | overdrive |
| ODN-MarkT-15-OD-01-CH1-VOL4_L.nam | 0.00400 | -17.7 | overdrive |
| ODN-MarkT-15-OD-01-CH1-VOL4_N.nam | 0.01296 | -17.3 | overdrive |
| ODN-MarkT-15-OD-01-CH1-VOL4_S.nam | 0.00209 | -17.6 | overdrive |
| ODN-MarkT-15-OD-01-CH1-VOL4_XS.nam | 0.00263 | -17.7 | overdrive |
| ODN-MarkT-15-OD-02-CH1-VOL4_C.nam | 0.00087 | -17.5 | overdrive |
| ODN-MarkT-15-OD-02-CH1-VOL4_F.nam | 0.00720 | -17.4 | overdrive |
| ODN-MarkT-15-OD-02-CH1-VOL4_L.nam | 0.00381 | -17.6 | overdrive |
| ODN-MarkT-15-OD-02-CH1-VOL4_N.nam | 0.01860 | -17.2 | overdrive |
| ODN-MarkT-15-OD-02-CH1-VOL4_S.nam | 0.00262 | -17.6 | overdrive |
| ODN-MarkT-15-OD-02-CH1-VOL4_XS.nam | 0.00328 | -17.6 | overdrive |
Les suffixes utilisés dans le tableau correspondent à :
- _S : Standard
- _XS : XStandard
- _C : Complex
- _L : Lite
- _F : Feather
- _N : Nano
On peut formuler deux remarques à la lecture de ce tableau :
- les architectures les plus complexes permettent d’obtenir les ESR les plus bas (les modèles les plus fidèles)
- les modèles high gain (et pire les fuzz, qui ne sont pas présentés dans cet exemple) ont des ESRs moins bons que les clean ou les crunch : ces types de sons sont en effet plus complexes à modéliser…
Si vous testez le pack exemple, vous devriez constater des différences assez flagrantes par exemple en partant du standard et en descendant vers Lite, Feather puis Nano. Pour autant, les modèles Lite et Feather ne sont pas ridicules en terme de rendu et peuvent déjà donner de bons résultats.
Dernier point : dans le cas ou l’on souhaiterait utiliser plusieurs modèles NAM simultanément (scénario d’un modèle pour une overdrive et d’un autre modèle pour un ampli), on pourra considérer l’utilisation de modèles light ou feather pour la partie pédale, les sons étant moins complexes à modéliser que ceux d’un ampli… : les modèles lite ou feather pourrait donc suffire pour produire de bons résultats…
Quelques mesures…
Pour apprécier les différences entre les architectures NAM discutées ci-dessus, cette section présente les résultats de null tests et les résultats obtenus en réalisant des mesures de réponse en fréquences entre les différentes architectures utilisées pour un même modèle. Attention, les null tests sont particulièrement sensibles et peuvent être faussés par de très nombreux paramètres, ils sont présentés ici dans le cadre d’une comparaison très restreinte (entre architecture d’un même modèle NAM) et dans un cadre très précis :
- comparaison du DI de l’ampli aux différentes déclinaisons d’un même modèle NAM en complex, standard,…
- modèle re-capturé dans les conditions identiques à l’enregistrement du DI de référence (MT15 Lead Gain 3)
- tous les enregistrements sont réalisés dans la fréquence native de 48 kHz
- plugin NAM standard en mode raw, calibrage réalisé en amont (même niveau de DI envoyé à l’ampli et au modèle)
- alignement manuel au sample près dans LogicProx, mesure LUFS-I par le Multimeter Logic et Fabfilter L2
- la comparaison AMP to AMP compare 2 enregistrements sur l’ampli de la piste de référence, avec phase inversée et donne un point de repère
- la piste de guitare utilisée comporte des accords et du jeu note à note, sur 40-50 secondes approximativement : on peut obtenir de meilleures valeurs LUFS en restreignant la comparaison à des sections plus courtes, avec moins de transients (par exemple : extinction d’accord sur quelques secondes) mais la comparaison devient alors -à mon sens- très partielle.
- les résultats sont normalisés en mode crête à – 12 dBFS.
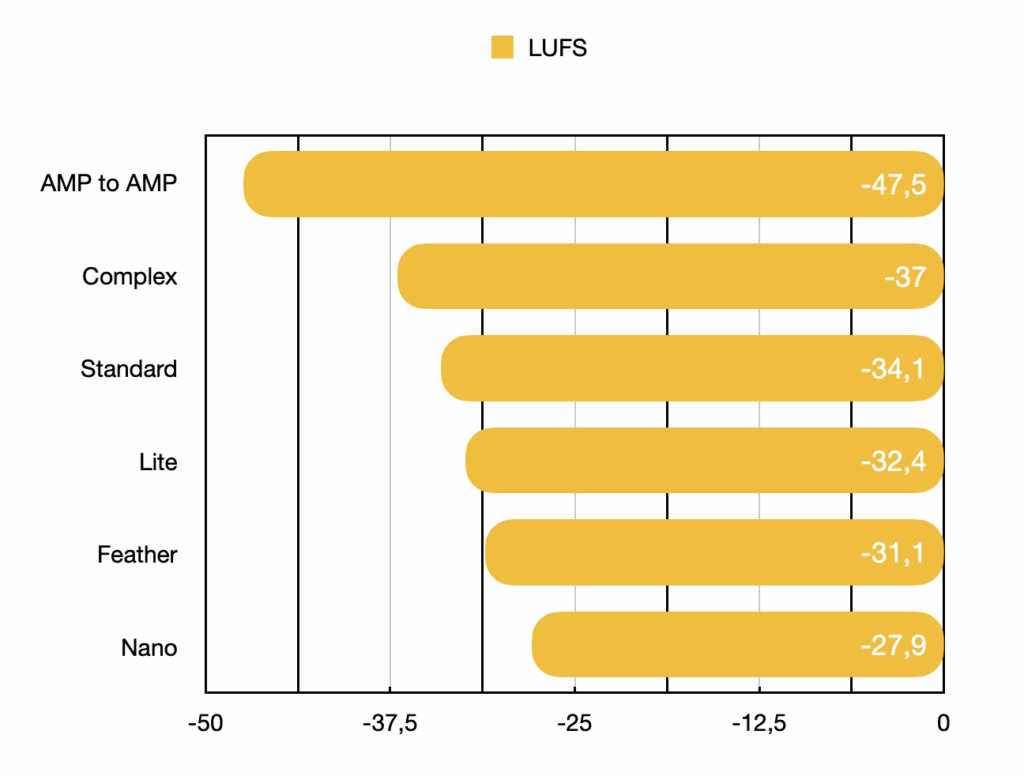
Les valeurs LUFS-I et les ESR des modèles de test sont les suivantes :
| Amp & Model to Amp | LUFS | ESR |
|---|---|---|
| AMP to AMP | -47,5 | - |
| Complex | -37 | 0,0054 |
| Standard | -34,1 | 0,0166 |
| Lite | -32,4 | 0,0230 |
| Feather | -31,1 | 0,0325 |
| Nano | -27,9 | 0,0505 |
Note : il s’agit d’un exemple de valeurs atteintes dans un contexte donné pour un modèle NAM particulier : on peut comparer les valeurs LUFS-I du test entre elles, mais il est inutile d’utiliser les valeurs absolues pour les comparer à d’autres null tests que vous pouvez trouver sur le net. Ces valeurs peuvent varier en utilisant un autre modèle (un autre ampli par exemple), avec des modèles calculés dans des conditions différentes ou avec un jeu d’essai différent….
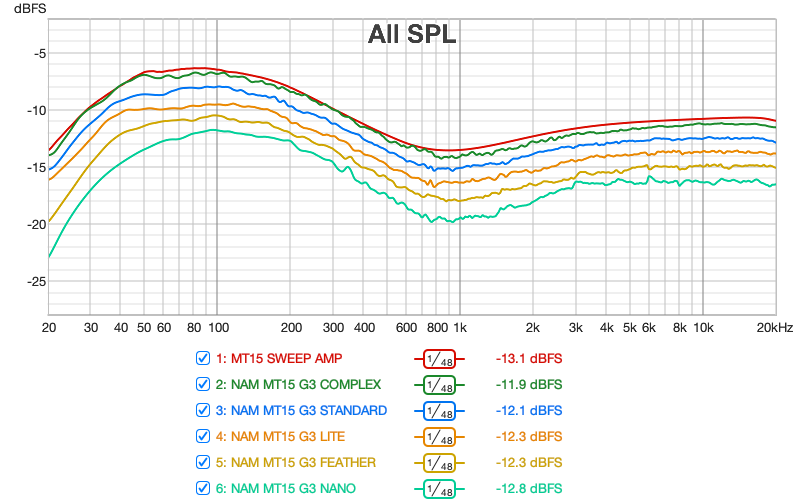
Le deuxième jeu de mesures est réalisé à l’aide du logiciel REW : il s’agit de mesures de réponse en fréquence de l’ampli et des différentes déclinaisons de modèles NAM, afin de visualiser l’impact de architectures (et donc potentiellement des valeurs ESR associées) sur la réponse en fréquence des modèles. Il s’agit de sweeps de 10 secondes, en rouge le sweep de l’ampli réel utilisé.Plugin NAM en mode Raw utilisé pour tous les modèles NAM.
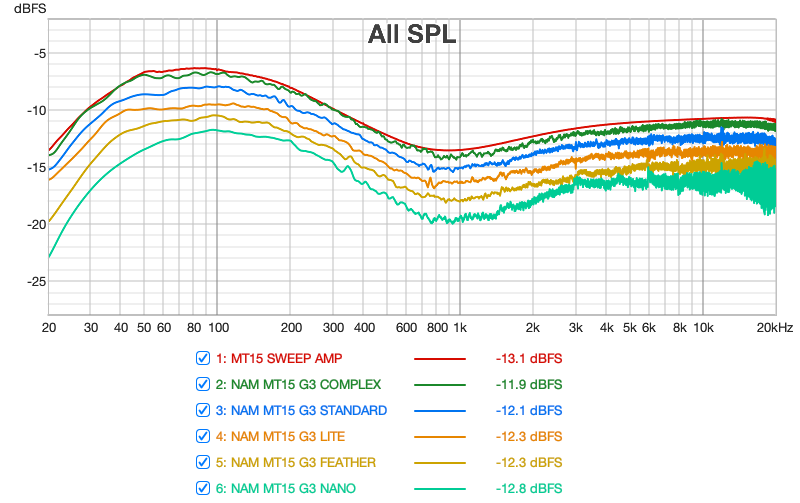
Sur cette première figure, on peut faire les observations suivantes :
- toutes les architectures reproduisent globalement très correctement la courbe de réponse en fréquence de l’ampli
- tous les courbes montrent des réponses en fréquence qui se dispersent de plus en plus fortement entre 1 kHz et 20 kHz (distorsion et bruit de hautes fréquences), phénomène relativement contenu sur le complex et le standard et qui s’amplifie à mesure que l’on descend en complexité d’architecture
- le graphe confirme des tests réalisés à l’écoute entre complex et standard : le complex est plus précis dans la réponse en basses et c’est celui dont la courbe colle au plus près de la réponse en fréquence originale.
Le graphe suivant présente les mêmes courbes en appliquant des filtres de lissage pour éliminer le bruit et les variations sur la partie fréquences hautes:
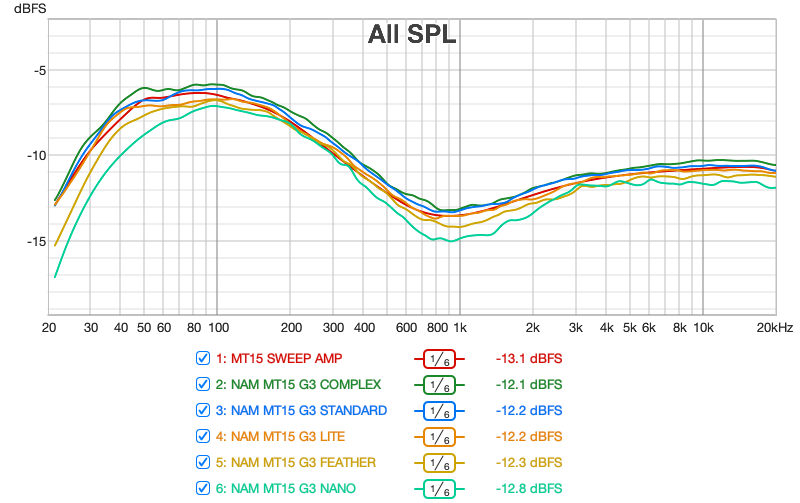
Et enfin, la même information avec un lissage moins fort et les courbes séparées :
Ressources CPU
Les informations présentées dans cette section ne sont ni exhaustives ni garanties, mais sont plutôt destinées à fournir des observations et des points de repères concernant l’utilisation des différentes architectures de modèles –dans une configuration spécifique– sur différentes catégories de machines, notamment du point de vue de la capacité à utiliser des modèles « en direct », c’est à dire de pouvoir pratiquer, répéter et potentiellement tracker ses enregistrements en temps réel, et ce soit à travers les applications NAM standalone, soit via un plugin dans une STAN. Il vous est vivement recommandé de tester par vous-meme la viabilité d’une configuration avant de vous lancer dans un achat de matériel, pour votre contexte et pour vos besoins.
Le tableau ci-dessous présente des observations de consommations CPU de l’application standalone Genome configurée spécifiquement avec une chaine simple utilisant un unique modèle NAM (voir un peu plus bas la configuration du test); et ces observations sont réalisées manuellement à partir de la lecture des informations présentées par Task Manager sous Windows et le moniteur d’activité sous OSX pour les tests sur matériels Apple. Les mesures sont des observations de valeurs « stabilisées », observées sur quelques dizaines de secondes après le chargement et l’utilisation d’un modèle NAM donné, mais notez que la consommation peut fluctuer autour des valeurs présentées.
Les pourcentages de consommation présentés sont également différents entre OSX et Windows : sur OSX, le maximum de consommation CPU est le nombre de coeurs * 100 : par exemple, sur une machine 8 coeurs le maximum est de 800%, et -par exemple- 110% représente l’utilisation d’un peu plus d’un coeur mais ne représente que 110/800 = 13,75% du total de la machine. A l’inverse, les valeurs données pour Windows sont en pourcentage de la capacité CPU totale de la machine : ainsi 20% sur une machine 4 coeurs est bien 20% du total de la capacité CPU, et notez qu’elle est également proche de la consommation maximale sur un coeur (100/4 = 25).
Attention également à l’aspect suivant : les machines les moins puissantes pourront plus facilement et plus rapidement être perturbées dès que votre système va réaliser d’autres tâches , par exemple l’exécution des systèmes de mises à jour, les scans d’antivirus/antimalware, les processus d’indexation,…ce qui peut avoir pour effet de perturber des applications audio comme NAM ou Genome standalone (interruptions, craquements, anomalies…). De manière similaire, si la machine est en limite de capacité sur le test (ie lorsqu’on se rapproche de l’utilisation d’un coeur complet de la machine), l’ajout d’autres effets pourra devenir rapidement problématique : en bref, il vaudra donc mieux avoir un peu de marge…
Notez également les points suivants, qui sont importants pour lire les mesures présentées :
- Version de Genome utilisée sous Mac et Windows : 1.10
- 1 seul et unique modèle NAM et un bloc IR loader chargé avec un mix de 2 IRs (100 ms)
- Configuration en mono (le mode stereo consomme un peu plus)
- Configuration de la carte son en 48 KHz / 128 samples : dans les tests que j’ai pu réaliser, l’utilisation de fréquences plus élevées engendre une consommation CPU significativement plus importante (downsampling/upsampling ?)
- Désactivation des animations dans Genome
- Utilisation de deux cartes sons avec pilotes ASIO sous Windows : SSL2+ MKII et Scarlett 2i2, Core Audio sous OSX.
- Oversampling de Genome désactivé (OFF)
- Et à titre d’indication, le tableau présente le score CPU Mark Single Thread du CPU rapporté par https://www.cpubenchmark.net
| OS/CPU | CPU | Complex | xStandard | Standard | Lite | Feather | Nano |
|---|---|---|---|---|---|---|---|
| OSX/M4 MAX 16C | 4562 | OK (33%) | OK (21%) | OK (20%) | OK (19%) | OK (17%) | OK (17%) |
| OSX/M1 PRO 8C | 3761 | OK (46%) | OK (30%) | OK (29%) | OK (27%) | OK (25%) | OK (23%) |
| Win11/Ryzen 6C | 2871 | OK (11-14%) | OK (3-7%) | OK (4-5%) | OK (3-4%) | OK (2-3%) | OK (2%) |
| Win11/I5-9600K 6C | 2727 | OK (15%) | OK (5%) | OK (5%) | OK (4-5%) | OK (4-5%) | OK (3-4%) |
| OSX/i5-8259U | 2190 | KO** | OK (53%) | OK (49%) | OK (44%) | OK (41%) | OK (37%) |
| Win11/N95 4C | 1927 | KO* | OK (15%) | OK (13%) | OK (12%) | OK (10%) | OK (9%) |
« * » : limite, instable, très sensible aux fluctuations : inutilisable
« ** » : 100% pour le host, 85% reporté par Genome, limite et instable
Informations complémentaires sur les CPU :
- Ryzen 6C : Ryzen 5 5625U 6C
- I5-9600K : I5-9600K @ 3.70 GHz 6C
- i5-8259U : i5-8259U @ 2.30GHz 4C
- N95 : Alder Lake N95 @ 1.70 Ghz 4C
Attention/disclaimer : dans le cadre de fréquences de travail différentes (88K, 176K…), avec des tailles de buffer plus élevées et dans le cadre de travail sous une STAN (enregistrement, mix), les puissances nécessaires peuvent être fortement différentes de celles présentées dans le tableau. Par exemple, en 176K/512 samples pour le Mac le plus ancien de la liste (8259U) , l’utilisation de modèle standard devient problématique, idem pour le xStandard sur la machine N95.
Sur des machines récentes et puissantes, les modèles les plus complexes ne posent pas de problèmes (33% pour le complexe sur le M4 Max ce qui correspond à une charge de 2% pour la machine…) et on constate qu’on arrive à faire tourner les modèles standards sur une vaste panoplie de machines, en tout cas dans les conditions du test présenté…
Alors pas de modèles xStandard ou Complex si on a pas de machine assez puissante ? Hé bien, il reste toujours la possibilité -dans le contexte de l’enregistrement et de la création de morceaux de musique- d’utiliser votre plugin NAM en offline dans votre STAN et de réaliser des bounce / freeze de vos pistes, une pratique classique lorsque l’on manipule des projets un peu complexes (en nombre de pistes et/ou en nombre de plugins) ou que l’on met à contribution des plugins qui nécessitent beaucoup de ressources. Le workflow de travail est un peu moins fluide mais il tout à fait envisageable et cela met à votre portée l’utilisation des modèles les plus fidèles même si vous ne disposez pas d’un monstre de puissance….
Conclusion
Après une introduction aux concepts fondamentaux des modèles NAM et de leur création, nous avons présenté les différentes architectures disponibles et leurs performances en terme de fidélité (ESR). La seconde partie a présenté le résultat d’observations pour donner des points de repères sur les machines et les puissances nécessaires pour faire tourner les différents types de modèles dans le contexte d’une utilisation « en direct ». Le prochain article sera consacré à un point essentiel pour tirer parti des modèles NAM : la gestion du gain.
Mention légale
Toutes les marques et tous les produits ou noms de sociétés mentionnés sur ce site et dans cet article peuvent être des marques déposées, appartenant à leurs propriétaires respectifs. Elles ne sont en aucun cas associées à Overdriven.fr ou au propriétaire d’overdriven.fr : leur mention n’implique aucun sponsoring ou association d’overdriven.fr/le propriétaire d’overdriven.fr avec ces marques. Ces marques ou noms de produits sont simplement utilisés pour décrire le matériel utilisé dans la création des profils ou modèles.
Change log
- Création : 12/08/2025
- Mise à jour : 22/08/2025, ajout null tests et sweep fréquences
Laisser un commentaire